Building a Multicloud Resource Data Lake Using CloudQuery
February 21, 2024There are many reasons why AWS customers will arrive in a situation where they have applications and infrastructure deployed in a multicloud environment.
These customers encounter many operational challenges with their applications distributed across a cloud estate that spans not only multiple Cloud Service Providers (CSPs) but also regions and accounts on AWS (or Subscriptions and Projects on other providers).
One particular challenge is gathering and maintaining accurate and current metadata about their cloud resources. This metadata can be extracted from all CSPs but the APIs and data schemas are not consistent which makes it difficult for customers to create a dataset that can drive their SecOps, ITOps and FinOps functions.
In this post, we describe how to build a multicloud resource data lake populated by open source CloudQuery, how to normalize the data to perform analytics against it, and provide recommendations for how to implement CloudQuery to operate at scale.
What is CloudQuery?
CloudQuery is a high-performance data integration tool that extracts, transforms, and loads data from cloud APIs to a variety of supported destinations such as databases and data lakes.
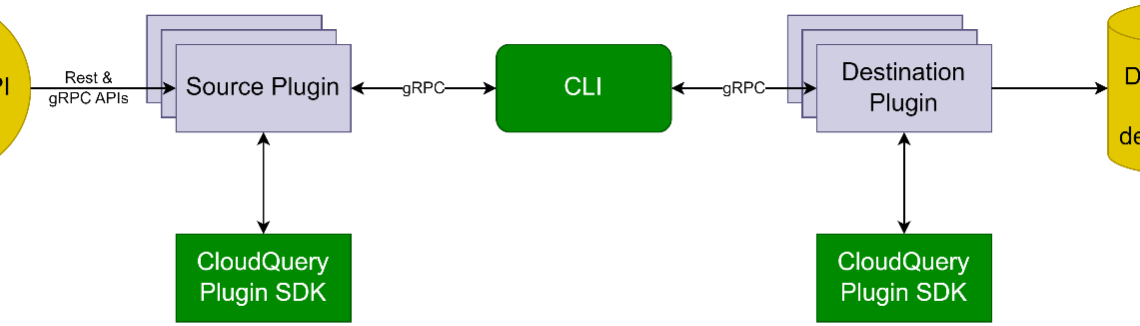
CloudQuery is an open source tool with an extensible, pluggable architecture that supports an ever-growing number of data sources and destinations. The CloudQuery CLI makes gRPC calls between the source and destination plugins. The source plugins handle initialization, authentication, and fetching of data with the external API, while the destination plugins handle authentication and data insertion to the destination. The CloudQuery Plugin SDK enables developers to extend CloudQuery by writing new source and destination plugins. See the CloudQuery Architecture for more information.

This post implements an example Multicloud Resource Data Lake using CloudQuery to harvest metadata from CSP APIs. We’ll populate an Amazon Simple Storage Service (Amazon S3) bucket, use AWS Glue to normalize the data, and then use Amazon Athena and Amazon Quicksight to analyze and visualize the data, as shown in the architectural diagram here.

CloudQuery Recommendations
CloudQuery is a command line executable binary that runs on Windows, MacOS, or Linux and can be deployed to run anywhere. When you execute a CloudQuery Sync you control it by passing it YAML configuration files that contain details of the Source and Destination plugins that CloudQuery will use. The configuration of the Destination plugins controls where and how CloudQuery will write the data it has retrieved from the Source plugins. The configuration of the Source plugins controls what endpoints CloudQuery will interrogate, how to authenticate with them, and what data to extract.
Depending on the size of your Cloud estate, the ratio between the number of CloudQuery Sources and Destinations you will need to manage will be many to few. In our use case for a Multicloud Resource Data Lake, the number of Destinations is likely to be limited to one or more Amazon S3 buckets and potentially a relational database. The Sources, however, will scale to equal the number of AWS Accounts, Microsoft Azure Subscriptions, and Google Cloud Platform (GCP) Projects in scope for data gathering. This scale creates some challenges around how you execute CloudQuery Syncs so that they complete in a reasonable time and avoid exhausting API quotas while interrogating the Sources. As the number of Sources you interrogate grows the cost of resources and managing the configuration of the CloudQuery Sync jobs can become onerous.
What follows are some recommendations from a customer solution that successfully gathers resource metadata from over 3,000 AWS Accounts.
Scale Out
Start by breaking the number of CloudQuery Sources into batches, as described in the Managing Configuration section, so that they can be scaled out and executed as multiple parallel CloudQuery Sync jobs. This enables control over how long the Syncs take to complete, ideally no more than 15 minutes each. Executing the Sync of each batch serially and ramping up at a rate of 1 every minute will help prevent a breach of API quotas that could be caused by a flood of API calls to all Sources at once.
Fine Tune
By default, CloudQuery will scan the APIs for every Service available from the Cloud Service Provider configured in the Source. The execution time and number of API calls can be further fine-tuned by specifying which Service APIs need to queried in the CloudQuery Configuration Files. For example, excluding AWS CloudTrail from the Source configuration will stop CloudQuery from harvesting events and writing these to the Destination and considerably reduce the time taken to complete a Sync of a single AWS Account. See the CloudQuery Plugin Configuration and Performance Tuning links for more information.
Hosting
To run CloudQuery at scale and Sync periodically you need to consider the best way to deploy infrastructure that simplifies management and optimizes for cost. For this we recommend executing CloudQuery Syncs in containers running Amazon Elastic Container Service (Amazon ECS) and AWS Fargate. CloudQuery maintains a container image in GitHub with the latest version of CloudQuery and all SDKs that the Source and Destination plugins require. Running CloudQuery as a Container Task on Amazon ECS and AWS Fargate means that you don’t have the overhead of managed infrastructure and you only pay for the CPU and memory consumed by the container while it is executing the Sync job. This means that your solution to populate your Multicloud Resource Data Lake is resilient, it elastically scales and it is cost efficient.
Managing Configuration and Execution of CloudQuery Syncs
Breaking down your cloud estate to execute in batches of CloudQuery Syncs that run in containers on ECS means that you have to consider how to create the configuration files and pass this to each CloudQuery batch for execution. The process for this is fairly straightforward:
1. Pull the list of sources, group them into the desired batch size, and generate the CloudQuery Config Files
2. Push the CloudQuery Config Files into the CloudQuery Container Images
3. Launch each Batch Container and execute the CloudQuery Sync to populate the Destination Amazon S3 Bucket

The size and elasticity of your cloud estate will influence the complexity of how you implement this. A static cloud estate with tens of Accounts, Subscriptions, or Projects will be easier to manage compared with one that is in the hundreds or thousands and frequently and rapidly fluctuates.
Here is a high-level architecture and workflow using a CI/CD pipeline that can scale to scan thousands of Sources.
Example Architecture

The diagram depicts eight steps to collect data from the Cloud Service Providers and send to an Amazon S3 Bucket in batches:
1. AWS CodePipeline deploys an Amazon ECS Task that launches the Batch Generator container
2. The Batch Generator queries the Cloud Service Providers for the Accounts, Subscriptions and Projects to be added as Sources in the CloudQuery Config files
3. The Batch Generator then groups the Accounts, Subscriptions and Projects into batches and writes the batches of CloudQuery Config files to Amazon S3
4. AWS CodeBuild pulls the CloudQuery Config Files from Amazon S3 and adds them to container images
5. AWS CodePipeline deploys an Amazon ECS Task for each container image
6. Each Amazon ECS Task launches its container image
7. The container images run the CloudQuery configurations to scan the Sources
8. CloudQuery writes the data gathered in the scan of the Sources to the Destination Amazon S3 Bucket
Resource Data Lake
We are now at the point where data coming from multiple cloud providers is stored on Amazon S3. But how do we query, transform, analyze, and visualize such data to get value out of it?
We can do so by implementing a well-known pattern for such scenarios, using three AWS services in conjunction:
· AWS Glue: for data discovery and cataloging of the data sources (the CloudQuery data on Amazon S3)
· Amazon Athena: for data normalization and analysis
· Amazon Quicksight: for data visualization and business intelligence
A possible Extract Transform and Load (ETL) pipeline includes an S3 bucket with CloudQuery raw data, an AWS Glue Crawler, an AWS Glue Database with metadata tables, Amazon Athena, and Amazon Quicksight as shown here:

This approach allows us to organize the tables containing data from CloudQuery in an AWS Glue Database. A Database can host multiple tables, so we only need to create a single database hosting tables coming from AWS, Google Cloud Platform (GCP), and Microsoft Azure.
Thanks to the Glue Crawler, we will add the CloudQuery data sources in the AWS Glue Data Catalog, making them available for us to query and analyze. When the crawler executes, for each of the CloudQuery tables (E.g. aws_ec2_instances), it will create a corresponding AWS Glue table and add it to the AWS Glue Database. By scheduling the AWS Glue Crawler to run on a recursive basis, we can ensure it will keep track of any schema change in the CloudQuery sources (E.g. changes in attributes or data sources).
Data Normalization
Each cloud provider has its own unique terminology, naming conventions, and structures for organizing and storing information. For example, Microsoft Azure has concepts like subscriptions, resource groups, and resource types, while AWS has accounts, regions, and service-specific constructs like Amazon Elastic Compute Cloud (Amazon EC2) instances and Amazon S3 buckets. Similarly, Google Cloud Platform (GCP) has its own set of concepts and naming conventions.
For such reasons, data normalization is necessary. By normalizing the extracted data, you can map and align these different concepts and terminologies into a unified schema. This enables consistent and standardized representation of the data, regardless of the cloud provider it originated from. Normalization allows you to establish a common language and structure, making it easier to aggregate, compare, and visualize the data across different providers in a cohesive and meaningful way.
Let’s take for example the concept of region: Although the location of the data centers varies across the different cloud providers, they are present at the same time in specific geographic areas, but they code such information differently. According to your use case, it can make sense to normalize this information and be able to group your cloud resources by the physical location in which they reside.
As an example, if we consider Germany as a geographical area (or more specifically, the city of Frankfurt), we can see how the cloud providers codify the information differently and store it in different fields. Considering the CloudQuery tables containing information on virtual machines (E.g.: Amazon EC2 in AWS terms), it would look like:
· AWS: region = 'eu-central-1'
· Azure: location = 'Germany West Central'
· GCP: machine type like '%europe-west-3%'
With AWS Glue and its ETL capabilities, we can first create a staging table for each of the raw tables generated by CloudQuery, and then a destination table containing all information on compute across the different cloud providers (E.g. mc_compute).
The staging table will be the first to introduce a uniform coding of the geographical area across different cloud providers, as shown in the diagram here.

We can use this destination table as the source of our analysis in Amazon Athena, and consequently as a source for the Amazon Quicksight dashboards and business intelligence activities.
Here is an example of how you can visualize the asset data collected across the three cloud providers under one single Amazon Quicksight dashboard.

Conclusion
CloudQuery is an open source tool that can help build a multicloud resource data lake by extracting infrastructure data from major cloud providers like AWS, Azure, and GCP. This data can then be queried and analyzed using AWS Glue, Amazon Athena, and Amazon Quicksight to gain actionable insights into your multicloud environment.
To run CloudQuery at scale, consider using Amazon ECS and AWS Fargate to run Sync in a container. CloudQuery maintains a container image in GitHub with the latest version of CloudQuery and all required SDKs, making it easy to download and execute as an Amazon ECS Task. This approach minimizes the overhead of managed infrastructure and simplifies the process of synchronizing data from multiple Cloud Service Providers and regions.
You can use CloudQuery for managing your accounts at scale, or build your own solution like the following articles describe: Building an Open-Source Cloud Asset Inventory with CloudQuery and Grafana, Attack Surface Management, Cloud Security Posture Management, Enrich AWS Cost and Usage Data with Infrastructure Data in Amazon Athena.
To get started building your own multicloud resource data lake using CloudQuery, visit cloudquery.io. The open source tool is easy to set up and the CloudQuery team offers enterprise support and professional services to help you implement at scale. Building a data lake of your infrastructure data across clouds has huge benefits — start your journey today!
