Announcing the Data Solutions Framework on AWS
February 14, 2024Today, we are excited to announce the release of Data Solutions Framework on AWS (DSF), an opinionated open source framework that accelerates building data solutions on AWS. It can take days or weeks to build end-to-end solutions on AWS with infrastructure as code (IaC) and following best practices, but with DSF it takes hours and you can focus on your use case.
About Data Solutions Framework on AWS
Building modern data platforms requires specialized skills across multiple domains such as infrastructure, security, networking, and distributed systems. It can be challenging to select the right tool for the job, while much of the effort goes into integrating different components which is undifferentiated work.
With DSF, data (platform) engineers can focus on their use case and business logic, and instead create a data platform from building blocks that represent common abstractions in data solutions such as a data lake. We built DSF based on our work with AWS customers and partners, and according to AWS Well-Architected framework. While DSF is an opinionated framework, it provides deep customization capabilities for developers to adapt what they build to their specific needs. You can easily customize, use a subset of the framework, extend your existing infrastructure with it, or simply fork the library to adapt to your needs.
DSF is built using AWS Cloud Development Kit (AWS CDK) to package infrastructure components into L3 CDK constructs atop AWS services. L3 Constructs are opinionated implementations of common technical patterns and generally create multiple resources that are configured to work with each other. We use L3 CDK Constructs to expose useful abstractions and patterns as building blocks for data solutions. For example, we provide a construct that creates a complete data lake storage solution with three different Amazon Simple Storage Service (Amazon S3) buckets, encryption, data lifecycle policies, and more. This means that you can create a data lake in your CDK application with just a few lines of code, and be sure it follows best practices and is thoroughly tested. DSF is available in TypeScript and Python packages through npm and PyPi respectively. You can use it in your AWS CDK application by simply installing it as a part of your project.
We will now go through key characteristics of the Data Solutions Framework on AWS, and show how you can benefit from it.
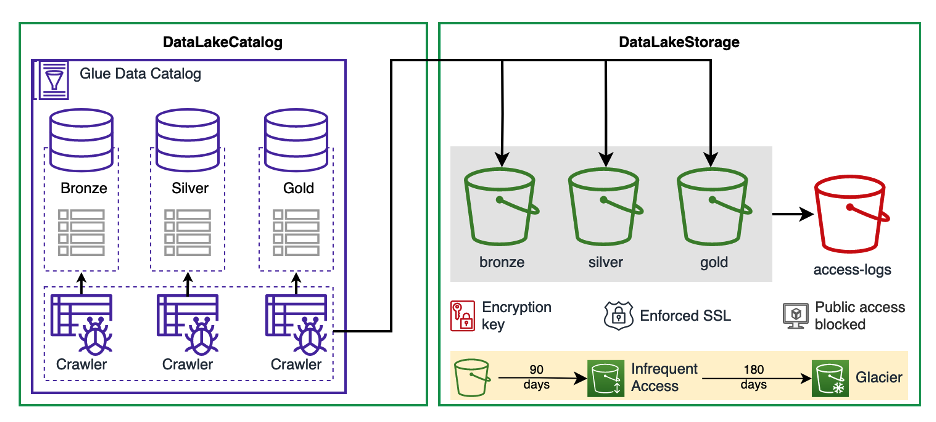
Accelerate delivery through integrated building blocks
DSF provides building blocks with smart defaults that are at the right level of abstraction to compose data solutions on AWS, while providing deep customization capabilities. Because building blocks are packaged as standard L3 AWS CDK Constructs, you can combine those with any other AWS CDK Construct to meet your specific needs. In other words, using DSF doesn’t exclude using AWS CDK constructs or those available through Construct Hub in your application. For example, let’s take a look at DataLakeStorage and DataLakeCatalog constructs.
 Using these building blocks, you can create a data lake for different data layers, integrated with AWS Key Management Service (AWS KMS) for server-side encryption, with access logs and other defaults. You can then connect it with a data catalog that configures AWS Glue databases and crawlers on top. And you can do this with just two lines of code:
Using these building blocks, you can create a data lake for different data layers, integrated with AWS Key Management Service (AWS KMS) for server-side encryption, with access logs and other defaults. You can then connect it with a data catalog that configures AWS Glue databases and crawlers on top. And you can do this with just two lines of code:
storage = dsf.storage.DataLakeStorage(self, "MyDataLakeStorage")
catalog = dsf.governance.DataLakeCatalog(self, "MyDataCatalog", data_lake_storage=storage)
Built-in best practices
We built DSF for production-ready workloads, hence each construct was designed according to AWS best practices. This includes least-privilege permissions, encryption everywhere, private deployments of purpose-built services, data deletion protection, and more. We use cdk-nag to enforce security and compliance for DSF. Cdk-nag provides identification and reporting mechanisms similar to what Static Application Security Testing (SAST) tools provide for applications. Constructs also encompass data analytics best practices as described in the Data Analytics Lens of Well-Architected Framework (AWS WAF). For example, we provide a multi-environment CI/CD pipeline for Apache Spark applications with support for integration tests (see in AWS WAF) as described in the following diagram.

You would usually need to write over a thousand lines of code to create infrastructure for such a solution using common IaC. With DSF you need less than a hundred lines of code, and can focus on your use case.
Fully customizable framework
While DSF provides building blocks with smart defaults and best practices, you can easily customize constructs for your specific needs with one of the following approaches:
- Change the default configuration:
Say you want to specify how objects are transitioned between different Amazon S3 storage classes. You consider that data is “hot” if it’s created less than a year ago. To achieve this, you can use DataLakeStorage object properties to change the default transition to infrequent access:
dsf.storage.DataLakeStorage(self, "MyDataLakeStorage", bronze_bucket_infrequent_access_delay=90, bronze_bucket_archive_delay=180, silver_bucket_infrequent_access_delay=180, silver_bucket_archive_delay=360, gold_bucket_infrequent_access_delay=180, gold_bucket_archive_delay=360
)
- Access AWS CDK or AWS CloudFormation resources and override any property:
In DSF, we expose all resources that constructs create, so you can either use those directly in your AWS CDK application (see line 5 below), or leverage AWS CDK escape hatches to customize, or decide to override AWS CloudFormation resources (lines 8 and 10 below) as shown in the code here:
# Create a data lake using DSF on AWS L3 construct
storage = dsf.storage.DataLakeStorage(self, "MyDataLakeStorage") # Access the AWS CDK L2 Bucket construct exposed by the L3 construct
storage.gold_bucket.add_to_resource_policy(myBucketPolicy) # Access the AWS CDK L1 Bucket construct exposed by the L3 construct
cfn_bucket = storage.gold_bucket.node.default_child
# Override the AWS CloudFormation property for transfer acceleration
cfn_bucket.add_override("Properties.AccelerateConfiguration.AccelerationStatus", "Enabled")
- Fork the repository and customize the library
DSF is open source under Apache 2.0 license. That means you can fork the repository, customize the code and publish your own version of the library. AWS CDK is object oriented, you can leverage standard development patterns like inheritance and composition to customize the constructs.
Conclusion
In this blog post, we introduced the Data Solutions Framework on AWS, an open source framework to simplify and accelerate the implementation of data solutions. With DSF, you can focus on your use case, and let the framework handle undifferentiated heavy lifting for you through extendable and customizable building blocks that are packaged as AWS CDK L3 Constructs with built-in best practices.
You can start experimenting today with DSF. We provide general documentation with examples and an in-depth overview of all currently available constructs. You can provide feedback on the GitHub repository via issues. Our roadmap is publicly available, and we look forward to your feature requests and contributions.
As we launch Data Solutions Framework on AWS, we would like to thank our AWS team for the outstanding work and efforts to make this available: Jan Michael Go, Alex Tarasov, Dmitry Balabanov, Jerome Van Der Linden, and Basri Dogan.
