Blue/Green deployments using AWS CDK Pipelines and AWS CodeDeploy
October 12, 2023Customers often ask for help with implementing Blue/Green deployments to Amazon Elastic Container Service (Amazon ECS) using AWS CodeDeploy. Their use cases usually involve cross-Region and cross-account deployment scenarios. These requirements are challenging enough on their own, but in addition to those, there are specific design decisions that need to be considered when using CodeDeploy. These include how to configure CodeDeploy, when and how to create CodeDeploy resources (such as Application and Deployment Group), and how to write code that can be used to deploy to any combination of account and Region.
Today, I will discuss those design decisions in detail and how to use CDK Pipelines to implement a self-mutating pipeline that deploys services to Amazon ECS in cross-account and cross-Region scenarios. At the end of this blog post, I also introduce a demo application, available in Java, that follows best practices for developing and deploying cloud infrastructure using AWS Cloud Development Kit (AWS CDK).
The Pipeline
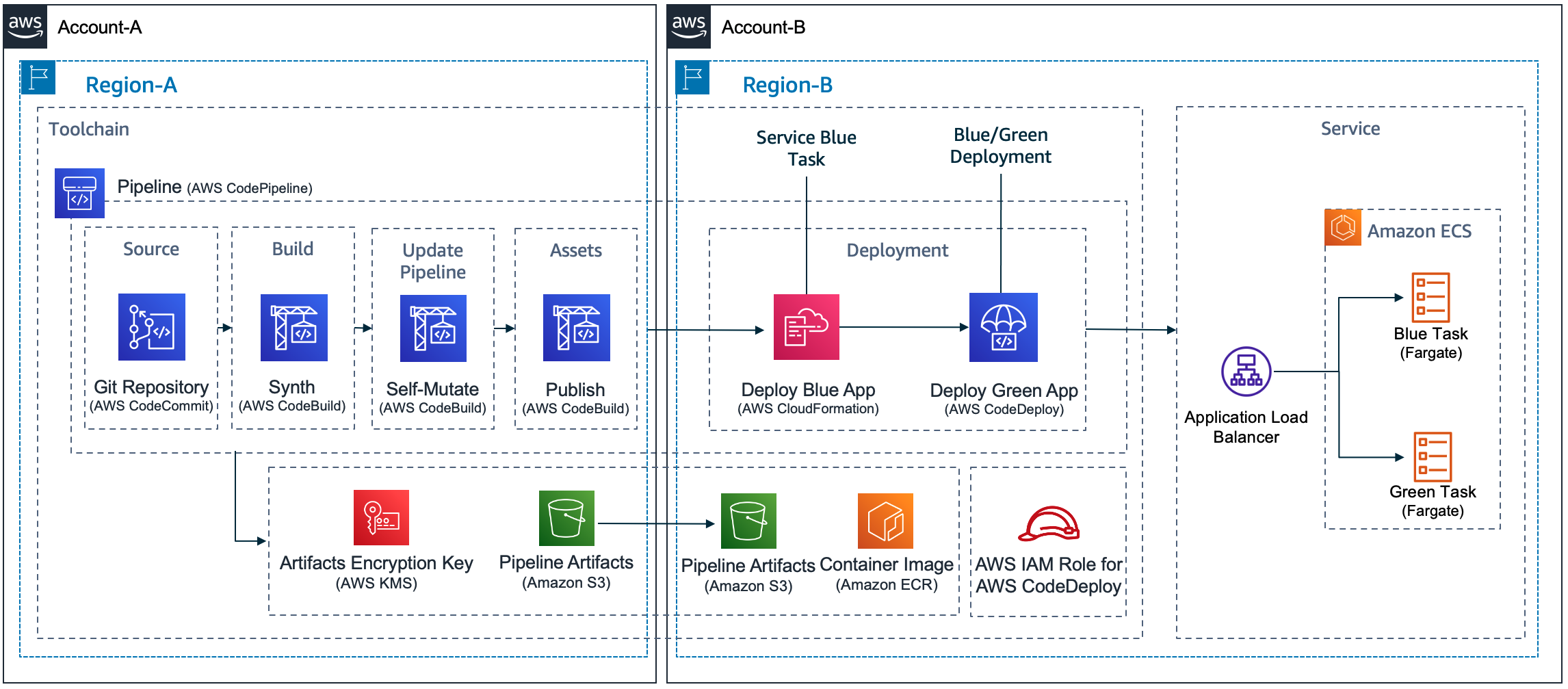
CDK Pipelines is an opinionated construct library used for building pipelines with different deployment engines. It abstracts implementation details that developers or infrastructure engineers need to solve when implementing a cross-Region or cross-account pipeline. For example, in cross-Region scenarios, AWS CloudFormation needs artifacts to be replicated to the target Region. For that reason, AWS Key Management Service (AWS KMS) keys, an Amazon Simple Storage Service (Amazon S3) bucket, and policies need to be created for the secondary Region. This enables artifacts to be moved from one Region to another. In cross-account scenarios, CodeDeploy requires a cross-account role with access to the KMS key used to encrypt configuration files. This is the sort of detail that our customers want to avoid dealing with manually.
AWS CodeDeploy is a deployment service that automates application deployment across different scenarios. It deploys to Amazon EC2 instances, On-Premises instances, serverless Lambda functions, or Amazon ECS services. It integrates with AWS Identity and Access Management (AWS IAM), to implement access control to deploy or re-deploy old versions of an application. In the Blue/Green deployment type, it is possible to automate the rollback of a deployment using Amazon CloudWatch Alarms.
CDK Pipelines was designed to automate AWS CloudFormation deployments. Using AWS CDK, these CloudFormation deployments may include deploying application software to instances or containers. However, some customers prefer using CodeDeploy to deploy application software. In this blog post, CDK Pipelines will deploy using CodeDeploy instead of CloudFormation.

Design Considerations
In this post, I’m considering the use of CDK Pipelines to implement different use cases for deploying a service to any combination of accounts (single-account & cross-account) and regions (single-Region & cross-Region) using CodeDeploy. More specifically, there are four problems that need to be solved:
CodeDeploy Configuration
The most popular options for implementing a Blue/Green deployment type using CodeDeploy are using CloudFormation Hooks or using a CodeDeploy construct. I decided to operate CodeDeploy using its configuration files. This is a flexible design that doesn’t rely on using custom resources, which is another technique customers have used to solve this problem. On each run, a pipeline pushes a container to a repository on Amazon Elastic Container Registry (ECR) and creates a tag. CodeDeploy needs that information to deploy the container.
I recommend creating a pipeline action to scan the AWS CDK cloud assembly and retrieve the repository and tag information. The same action can create the CodeDeploy configuration files. Three configuration files are required to configure CodeDeploy: appspec.yaml, taskdef.json and imageDetail.json. This pipeline action should be executed before the CodeDeploy deployment action. I recommend creating template files for appspec.yaml and taskdef.json. The following script can be used to implement the pipeline action:
##
#!/bin/sh
#
# Action Configure AWS CodeDeploy
# It customizes the files template-appspec.yaml and template-taskdef.json to the environment
#
# Account = The target Account Id
# AppName = Name of the application
# StageName = Name of the stage
# Region = Name of the region (us-east-1, us-east-2)
# PipelineId = Id of the pipeline
# ServiceName = Name of the service. It will be used to define the role and the task definition name
#
# Primary output directory is codedeploy/. All the 3 files created (appspec.json, imageDetail.json and # taskDef.json) will be located inside the codedeploy/ directory
#
##
Account=$1
Region=$2
AppName=$3
StageName=$4
PipelineId=$5
ServiceName=$6
repo_name=$(cat assembly*$PipelineId-$StageName/*.assets.json | jq -r '.dockerImages[] | .destinations[] | .repositoryName' | head -1) tag_name=$(cat assembly*$PipelineId-$StageName/*.assets.json | jq -r '.dockerImages | to_entries[0].key') echo ${repo_name} echo ${tag_name} printf '{"ImageURI":"%s"}' "$Account.dkr.ecr.$Region.amazonaws.com/${repo_name}:${tag_name}" > codedeploy/imageDetail.json sed 's#APPLICATION#'$AppName'#g' codedeploy/template-appspec.yaml > codedeploy/appspec.yaml sed 's#APPLICATION#'$AppName'#g' codedeploy/template-taskdef.json | sed 's#TASK_EXEC_ROLE#arn:aws:iam::'$Account':role/'$ServiceName'#g' | sed 's#fargate-task-definition#'$ServiceName'#g' > codedeploy/taskdef.json cat codedeploy/appspec.yaml
cat codedeploy/taskdef.json
cat codedeploy/imageDetail.json
Using a Toolchain
A good strategy is to encapsulate the pipeline inside a Toolchain to abstract how to deploy to different accounts and regions. This helps decoupling clients from the details such as how the pipeline is created, how CodeDeploy is configured, and how cross-account and cross-Region deployments are implemented. To create the pipeline, deploy a Toolchain stack. Out-of-the-box, it allows different environments to be added as needed. Depending on the requirements, the pipeline may be customized to reflect the different stages or waves that different components might require. For more information, please refer to our best practices on how to automate safe, hands-off deployments and its reference implementation.
In detail, the Toolchain stack follows the builder pattern used throughout the CDK for Java. This is a convenience that allows complex objects to be created using a single statement:
Toolchain.Builder.create(app, Constants.APP_NAME+"Toolchain") .stackProperties(StackProps.builder() .env(Environment.builder() .account(Demo.TOOLCHAIN_ACCOUNT) .region(Demo.TOOLCHAIN_REGION) .build()) .build()) .setGitRepo(Demo.CODECOMMIT_REPO) .setGitBranch(Demo.CODECOMMIT_BRANCH) .addStage( "UAT", EcsDeploymentConfig.CANARY_10_PERCENT_5_MINUTES, Environment.builder() .account(Demo.SERVICE_ACCOUNT) .region(Demo.SERVICE_REGION) .build()) .build();
In the statement above, the continuous deployment pipeline is created in the TOOLCHAIN_ACCOUNT and TOOLCHAIN_REGION. It implements a stage that builds the source code and creates the Java archive (JAR) using Apache Maven. The pipeline then creates a Docker image containing the JAR file.
The UAT stage will deploy the service to the SERVICE_ACCOUNT and SERVICE_REGION using the deployment configuration CANARY_10_PERCENT_5_MINUTES. This means 10 percent of the traffic is shifted in the first increment and the remaining 90 percent is deployed 5 minutes later.
To create additional deployment stages, you need a stage name, a CodeDeploy deployment configuration and an environment where it should deploy the service. As mentioned, the pipeline is, by default, a self-mutating pipeline. For example, to add a Prod stage, update the code that creates the Toolchain object and submit this change to the code repository. The pipeline will run and update itself adding a Prod stage after the UAT stage. Next, I show in detail the statement used to add a new Prod stage. The new stage deploys to the same account and Region as in the UAT environment:
... .addStage( "Prod", EcsDeploymentConfig.CANARY_10_PERCENT_5_MINUTES, Environment.builder() .account(Demo.SERVICE_ACCOUNT) .region(Demo.SERVICE_REGION) .build()) .build();
In the statement above, the Prod stage will deploy new versions of the service using a CodeDeploy deployment configuration CANARY_10_PERCENT_5_MINUTES. It means that 10 percent of traffic is shifted in the first increment of 5 minutes. Then, it shifts the rest of the traffic to the new version of the application. Please refer to Organizing Your AWS Environment Using Multiple Accounts whitepaper for best-practices on how to isolate and manage your business applications.
Some customers might find this approach interesting and decide to provide this as an abstraction to their application development teams. In this case, I advise creating a construct that builds such a pipeline. Using a construct would allow for further customization. Examples are stages that promote quality assurance or deploy the service in a disaster recovery scenario.
The implementation creates a stack for the toolchain and another stack for each deployment stage. As an example, consider a toolchain created with a single deployment stage named UAT. After running successfully, the DemoToolchain and DemoService-UAT stacks should be created as in the next image:

CodeDeploy Application and Deployment Group
CodeDeploy configuration requires an application and a deployment group. Depending on the use case, you need to create these in the same or in a different account from the toolchain (pipeline). The pipeline includes the CodeDeploy deployment action that performs the blue/green deployment. My recommendation is to create the CodeDeploy application and deployment group as part of the Service stack. This approach allows to align the lifecycle of CodeDeploy application and deployment group with the related Service stack instance.
CodePipeline allows to create a CodeDeploy deployment action that references a non-existing CodeDeploy application and deployment group. This allows us to implement the following approach:
- Toolchain stack deploys the pipeline with CodeDeploy deployment action referencing a non-existing CodeDeploy application and deployment group
- When the pipeline executes, it first deploys the Service stack that creates the related CodeDeploy application and deployment group
- The next pipeline action executes the CodeDeploy deployment action. When the pipeline executes the CodeDeploy deployment action, the related CodeDeploy application and deployment will already exist.
Below is the pipeline code that references the (initially non-existing) CodeDeploy application and deployment group.
private IEcsDeploymentGroup referenceCodeDeployDeploymentGroup( final Environment env, final String serviceName, final IEcsDeploymentConfig ecsDeploymentConfig, final String stageName) { IEcsApplication codeDeployApp = EcsApplication.fromEcsApplicationArn( this, Constants.APP_NAME + "EcsCodeDeployApp-"+stageName, Arn.format(ArnComponents.builder() .arnFormat(ArnFormat.COLON_RESOURCE_NAME) .partition("aws") .region(env.getRegion()) .service("codedeploy") .account(env.getAccount()) .resource("application") .resourceName(serviceName) .build())); IEcsDeploymentGroup deploymentGroup = EcsDeploymentGroup.fromEcsDeploymentGroupAttributes( this, Constants.APP_NAME + "-EcsCodeDeployDG-"+stageName, EcsDeploymentGroupAttributes.builder() .deploymentGroupName(serviceName) .application(codeDeployApp) .deploymentConfig(ecsDeploymentConfig) .build()); return deploymentGroup;
}
To make this work, you should use the same application name and deployment group name values when creating the CodeDeploy deployment action in the pipeline and when creating the CodeDeploy application and deployment group in the Service stack (where the Amazon ECS infrastructure is deployed). This approach is necessary to avoid a circular dependency error when trying to create the CodeDeploy application and deployment group inside the Service stack and reference these objects to configure the CodeDeploy deployment action inside the pipeline. Below is the code that uses Service stack construct ID to name the CodeDeploy application and deployment group. I set the Service stack construct ID to the same name I used when creating the CodeDeploy deployment action in the pipeline.
// configure AWS CodeDeploy Application and DeploymentGroup EcsApplication app = EcsApplication.Builder.create(this, "BlueGreenApplication") .applicationName(id) .build(); EcsDeploymentGroup.Builder.create(this, "BlueGreenDeploymentGroup") .deploymentGroupName(id) .application(app) .service(albService.getService()) .role(createCodeDeployExecutionRole(id)) .blueGreenDeploymentConfig(EcsBlueGreenDeploymentConfig.builder() .blueTargetGroup(albService.getTargetGroup()) .greenTargetGroup(tgGreen) .listener(albService.getListener()) .testListener(listenerGreen) .terminationWaitTime(Duration.minutes(15)) .build()) .deploymentConfig(deploymentConfig) .build();
CDK Pipelines roles and permissions
CDK Pipelines creates roles and permissions the pipeline uses to execute deployments in different scenarios of regions and accounts. When using CodeDeploy in cross-account scenarios, CDK Pipelines deploys a cross-account support stack that creates a pipeline action role for the CodeDeploy action. This cross-account support stack is defined in a JSON file that needs to be published to the AWS CDK assets bucket in the target account. If the pipeline has the self-mutation feature on (default), the UpdatePipeline stage will do a cdk deploy to deploy changes to the pipeline. In cross-account scenarios, this deployment also involves deploying/updating the cross-account support stack. For this, the SelfMutate action in UpdatePipeline stage needs to assume CDK file-publishing and a deploy roles in the remote account.
The IAM role associated with the AWS CodeBuild project that runs the UpdatePipeline stage does not have these permissions by default. CDK Pipelines cannot grant these permissions automatically, because the information about the permissions that the cross-account stack needs is only available after the AWS CDK app finishes synthesizing. At that point, the permissions that the pipeline has are already locked-in. Hence, for cross-account scenarios, the toolchain should extend the permissions of the pipeline’s UpdatePipeline stage to include the file-publishing and deploy roles.
In cross-account environments it is possible to manually add these permissions to the UpdatePipeline stage. To accomplish that, the Toolchain stack may be used to hide this sort of implementation detail. In the end, a method like the one below can be used to add these missing permissions. For each different mapping of stage and environment in the pipeline it validates if the target account is different than the account where the pipeline is deployed. When the criteria is met, it should grant permission to the UpdatePipeline stage to assume CDK bootstrap roles (tagged using key aws-cdk:bootstrap-role) in the target account (with the tag value as file-publishing or deploy). The example below shows how to add permissions to the UpdatePipeline stage:
private void grantUpdatePipelineCrossAccoutPermissions(Map<String, Environment> stageNameEnvironment) { if (!stageNameEnvironment.isEmpty()) { this.pipeline.buildPipeline(); for (String stage : stageNameEnvironment.keySet()) { HashMap<String, String[]> condition = new HashMap<>(); condition.put( "iam:ResourceTag/aws-cdk:bootstrap-role", new String[] {"file-publishing", "deploy"}); pipeline.getSelfMutationProject() .getRole() .addToPrincipalPolicy(PolicyStatement.Builder.create() .actions(Arrays.asList("sts:AssumeRole")) .effect(Effect.ALLOW) .resources(Arrays.asList("arn:*:iam::" + stageNameEnvironment.get(stage).getAccount() + ":role/*")) .conditions(new HashMap<String, Object>() {{ put("ForAnyValue:StringEquals", condition); }}) .build()); } }
}
The Deployment Stage
Let’s consider a pipeline that has a single deployment stage, UAT. The UAT stage deploys a DemoService. For that, it requires four actions: DemoService-UAT (Prepare and Deploy), ConfigureBlueGreenDeploy and Deploy.

The DemoService-UAT.Deploy action will create the ECS resources and the CodeDeploy application and deployment group. The ConfigureBlueGreenDeploy action will read the AWS CDK cloud assembly. It uses the configuration files to identify the Amazon Elastic Container Registry (Amazon ECR) repository and the container image tag pushed. The pipeline will send this information to the Deploy action. The Deploy action starts the deployment using CodeDeploy.
Solution Overview
As a convenience, I created an application, written in Java, that solves all these challenges and can be used as an example. The application deployment follows the same 5 steps for all deployment scenarios of account and Region, and this includes the scenarios represented in the following design:
Conclusion
In this post, I identified, explained and solved challenges associated with the creation of a pipeline that deploys a service to Amazon ECS using CodeDeploy in different combinations of accounts and regions. I also introduced a demo application that implements these recommendations. The sample code can be extended to implement more elaborate scenarios. These scenarios might include automated testing, automated deployment rollbacks, or disaster recovery. I wish you success in your transformative journey.
